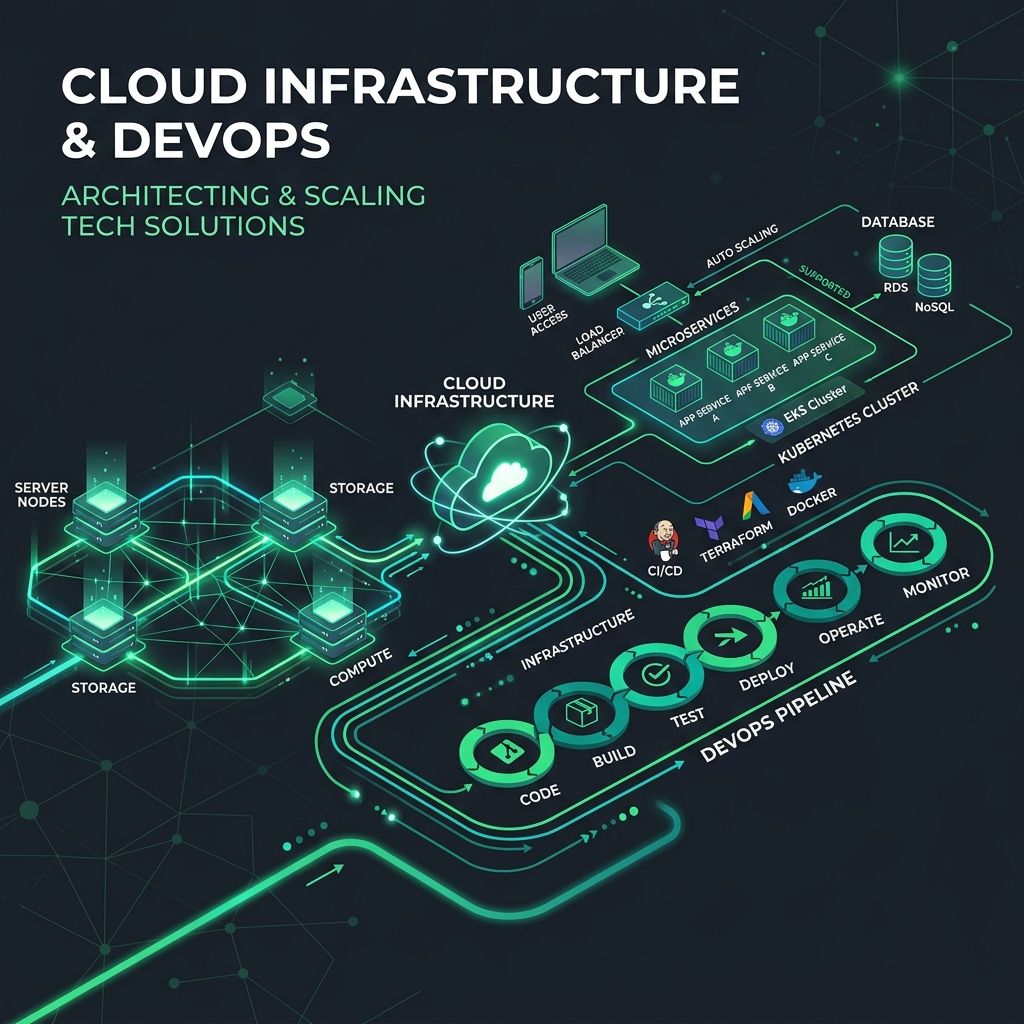
Cloud infrastructure decisions have a long-lasting impact on application performance, team productivity, and operational cost. After architecting and deploying dozens of applications across AWS, GCP, and Azure, we've developed strong opinions about which patterns apply where.
The Serverless Revolution (and Its Limits)
Serverless functions — AWS Lambda, Google Cloud Functions, Azure Functions — are genuinely transformative for the right workloads. Event-driven processing, lightweight API endpoints, scheduled jobs, and webhook handlers are all excellent serverless use cases. The operational overhead is minimal, scaling is automatic, and cost is proportional to actual usage.
The limits become apparent at scale and for stateful workloads. Cold start latency, execution time limits, and the complexity of managing distributed state across function invocations create real engineering challenges. Applications with sustained high traffic often find containerized services more cost-effective than serverless beyond certain thresholds.
Container Orchestration with Kubernetes
Kubernetes has become the de facto standard for container orchestration, though its complexity is frequently underestimated. Managed Kubernetes services (EKS, GKE, AKE) have significantly reduced the operational burden, but you still need engineers who understand pod scheduling, resource limits, ingress configuration, and horizontal pod autoscaling.
For teams that need fine-grained control over resource allocation and have the expertise to manage it, Kubernetes is extraordinarily capable. For teams that don't, managed platforms like Railway, Render, or Google Cloud Run often deliver 80% of the capability with 20% of the operational burden.
Edge Computing in Practice
Edge computing distributes computation geographically, processing requests in data centers closest to the end user. For globally distributed applications, this can reduce latency from hundreds of milliseconds to single digits for users far from your primary region.
Cloudflare Workers, Vercel Edge Functions, and Fastly Compute@Edge are the leading platforms. The constraint is that edge runtimes operate in sandboxed environments with limited APIs — no full Node.js runtime, restricted file system access, and typically short execution time limits. These constraints push toward stateless, lightweight computation, which maps well to authentication, A/B testing, localization, and content transformation use cases.
Database Architecture for Scale
The database tier is where many scaling challenges originate. We've found that most applications benefit from a combination of a primary relational database for transactional data (Postgres remains our default), a caching layer for read-heavy workloads (Redis), and a full-text search engine for search functionality (Elasticsearch or Meilisearch).
The shift to managed database services has been profound. PlanetScale (MySQL-compatible with schema branching), Neon (serverless Postgres), and Supabase have dramatically lowered the barrier to production-grade database infrastructure.
Our Infrastructure Philosophy
Start simple. A single well-configured virtual machine can serve thousands of users. Add architectural complexity only when you have concrete evidence — measured performance data, specific scaling requirements — that simpler approaches are insufficient.
Premature architectural complexity is one of the most common and costly mistakes we see in new projects. Start with what's sufficient, measure carefully, and evolve the architecture based on real constraints.